|
在SQLServer数据库中,当我们对一个位于同步链上的表进行更新时,如果更新的记录数也非常多,几百或是几千万,那么批量更新该表会造成同步链的大量延时(甚至有可能崩溃掉,即使同步链不崩溃,等的人也要崩溃了)。
原因: 一般情况下,Replication是根据我们更改的数据一条条更改记录的,也就是说我们在发布端下达如下的语句:
update TestTb set TT='xxxx' where ustate=0
如果这条更新语句,修改的数据量是一千万条的话,那Replication同步链需要传递一千万条如下的语句到订阅端去执行:
exec [dbo].[sp_MSupd_dboTestTb] default,'xxxx',default,2,0x02
如果我们有8台订阅端,而我们更新的数据也不是这么简单的数据的话(如更新一些nvarchar(1000)之类的),这个数据流量是非常恐怖的。
解决办法: 基于以上原因,我们在对同步链上的表进行大规模更新操作时,必须要非常小心,避免数据的大量更新;但是如果业务有此要求,必须要在同步的表上更新这么多数据量,如何办呢?
1. 如果你已经在发布端直接运行了类似上面的语句,那就只有一个字:“等”;
2. 我们可以采用分批处理的方式来更新同步链,一批次处理几百或者一千条数据,处理完一批后,等待10s钟,再运行下一批,类似语句如下(常用):
DECLARE @count int ,@sumcount int ,@subcount int SET @sumcount=0 set @subcount=0 SELECT @count=COUNT(0) FROM TestTb where ustate=0 WHERE ustate=0
WHILE(@sumcount<@count and @subcount >= 1000) begin UPDATE TOP (1000) TestTb SET TT='XXXX' where ustate=0 set @subcount=@@ROWCOUNT set @sumcount=@sumcount+1000 waitfor delay '00:00:10' end
3. 如果更新的数据很大,用第二种方法将会消耗很长的时间,等不起呀;有没有更好的方法呢?我们可以通过使用临时存储过程来更新数据,下面我们通过一个实例来看看如何操作: --新建一个测试表 CREATE TABLE TestTb ( id int identity(1,1) primary key , ,name varchar(20) ,ustate smallint )
--插入测试数据 insert into TestTb(name,ustate) values('AAAAA',0), ('BBBBB',1), ('CCCCC',0), ('DDDDD',1), ('EEEEE',0), ('FFFFF',1)
--新建一个存储过程 create proc usp_updateTestTb as begin update TestTb set name='KKKKKK' where ustate=1 end
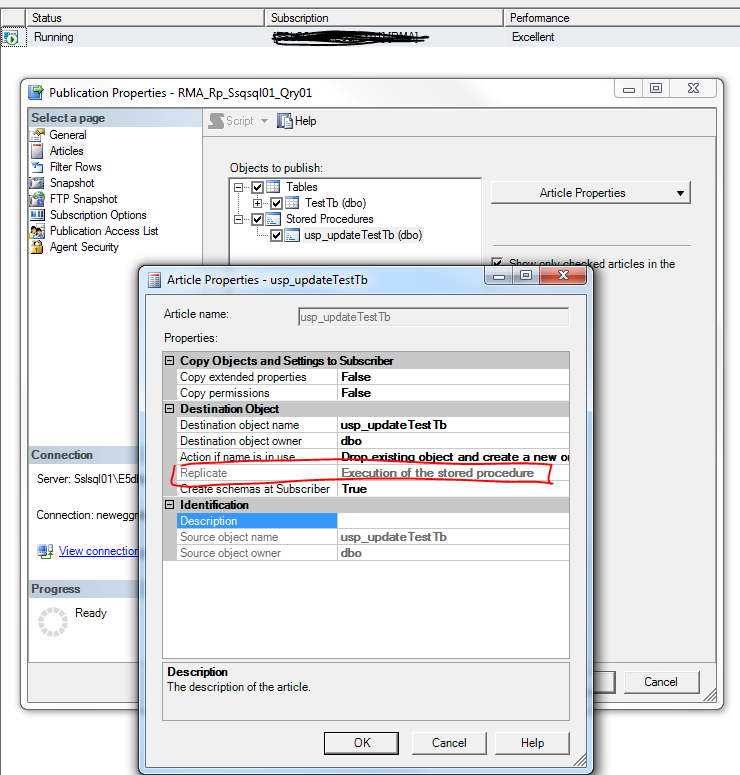
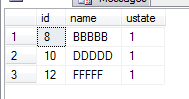
我们把表TestTb 和 usp_updateTestTb 都建到同步链上,需要注意的是,TestTb表结构在订阅端需要将Identity 属性去掉;usp_updateTestTb需要选择同步更改和运行,即将同步的Replicate属性 选为“Execution of the stored procedure”,这样在发布端执行存储过程时,订阅端也会执行相应的存储过程,而不是分条执行存储过程中影响的每一条语句; 同步建好后,我们在订阅端打开Profile,选择我们要跟踪的库,然后在订阅端做以下测试: --先查下满足记录的条数 select * from TestTb where ustate=1
--直接运行更改语句 update TestTb set name='PPPPPP' where ustate=1
(3 row(s) affected)
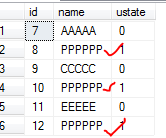
--更改后订阅端的数据 select * from TestTb
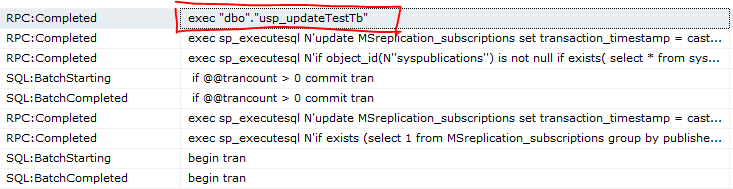
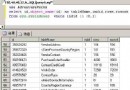
我们到订阅端的Profile中去看看传递过来的语句情况: s 可以看到有三条语句传过来了; 接下来我们运行存储过程usp_updateTestTb,这个SP也是更新TestTb中三条数据,我们看看Profile中又有什么信息
--发布端运行usp_updateTestTb exec usp_updateTestTb
(3 row(s) affected)
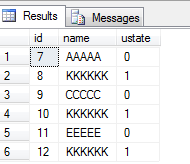
--订阅段数据 select * from TestTb
订阅端Profile的数据:
图中我们可以看到,订阅端也只是运行了usp_updateTestTb这个存储过程,并不会传递三条修改的记录过来,如果这个sp更新的数据很大,这样将大大减少同步链传递的数据量(如果我们更改的记录是一千万,传递的也就一条命令),数据的更新只相当于本地库的更新,对同步链没有影响;同时,基于对系统影响的考虑,我们把方法二和方法三两中方法结合起来运用,能收到很不错的效果。 |