一. 问题背景
-
数据源
hive数据表结构如下

其中info字段的数据类型为string格式的复杂json结构,例如:
[{“name”:“Tom”, “city”:“Beijing”},{“name”:“Jack”, “city”:“Shanghai”},{“name”:“Bill”, “city”:“Tianjin”}]
-
需求
现在需要统计每个id 中info字段所对应的用户数量,而最关键的一步就是将数据解析为如下类型:
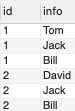
二. 解决方法
-
HQL代码
先把代码放上来
SELECT
`id`,
get_json_object(concat('{',names,'}'),'$.name') as passengername
FROM test
LATERAL VIEW explode(split(regexp_replace(regexp_replace(info,'\\[\\{',''),'}]',''),'},\\{'))names as names
WHERE day>'2020-05-01'
GROUP BY id;
-
相关函数
-
REGEXP_REPLACE(string INITIAL_STRING, string PATTERN, string REPLACEMENT)
这个函数的作用为将某一字段中具有某种格式的文本替换为另一种文本。
其中第一个参数为字段,第二个参数为要替换的文本格式,第三个参数为替换后的目标格式,第二第三个参数均使用正则表达。
-
SPLIT(string str, string pat)
这个函数的用来将字符串分割,第一个参数为操作的字符串,第二个参数为分割符。
-
LATERAL VIEW EXPLODE()
行转列,将一个字段内的内容拆成多行
-
CONCAT()
将多个字符串合并为一个
-
get_jason_object(column, "$.parameter")
用于解析json类型的数据,第一个参数是选择的字段,第二个参数是json数据中选择的参数
-
代码解析
regexp_replace(regexp_replace(info,'\\[\\{',''),'}]','')
通过两层嵌套去掉了最外层的[ { } ] 括号
split(regexp_replace(regexp_replace(info,'\\[\\{',''),'}]',''),'},\\{')
通过‘{’ ‘}’将几个json数据分开
LATERAL VIEW explode(split(regexp_replace(regexp_replace(info,'\\[\\{',''),'}]',''),'},\\{'))names as names
将几个json文本拆分成多行
get_json_object(concat('{',names,'}'),'$.name') as passengername
由于字符串切割的时候把每个json的大括号去了,所以使用get_json_object()时要先再加上两个大括号
-
容易踩的坑
当我把代码写好运行之后发现有报错,我猜测是lateral view explode()这一行的问题,后来一排查发现果然是这儿的问题,我一开始的代码是
LATERAL VIEW explode()as names
正确的语法应该是
LATERAL VIEW explode()names as names
|