问题描述
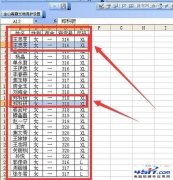
读取excel,却出现了如下错误。
u'1.G1P0\u5b5539+6\u5468LOA\u5355\u6d3b\u80ce\u987a\u4ea72.\u598a\u5a20\u671f\u7cd6\u5c3f\u75c53\u3001\u4f1a\u9634I\u5ea6\u88c2\u4f244.
问题解决
方式一:
终归还是编码的问题。主要起作用的是先decode再进行encode操作。
def read_xls(io_path):
sheet = pd.read_excel(io_path, encoding='utf8')
print str(sheet.values[1]).decode("unicode_escape").encode("utf8")
参考原因: 为什么是这样? 控制器显示的字符是UTF8的,所以最后需要encode成UTF8的,2.为什么要用decode? 因为要encode成UTF8,得是unicode格式的字符串才行,但是默认的字符串是str型的,所有需要把其他的字符编码转成UNICODE才行,然后,因为打印出来的乱码是. u'\XXX' 这种形式, 所以根据经验应该是unicode_escape形式。
方式二
方式一有点逃避问题,额,经过反复试验,方式二更加靠谱。
def read_xls(io_path):
sheet = pd.read_excel(io_path, encoding='utf-8')
for item in sheet.values:
item_con = item[0]
print item_con
|