|
��� ����XML�����Ϊ����չ������ԣ�Extensible Markup Language������һ�����������������Լ��ı�ǵı�����ԡ�������ά��Э�ᣨW3C�������������˷� HTML�������ı�������ԣ�Hypertext Markup Language��������������ҳ�Ļ������ľ��ޡ��� HTML һ����XML ���� SGML �D ��ͨ�ñ�����ԣ�Standard Generalized Markup Language�������� SGML ���ڳ���ҵʹ������ʮ�꣬�������ⷽ��ĸ�����ʹ���౾����ʹ������������ȴ����SGML Ҳ�������������ܰ����������Ժ���ã�Sounds great, maybe later��������XML ��Ϊ Web ��Ƶġ� ����Ϊʲô��Ҫ XML�� ����HTML ʼ������ɹ��ı�����ԡ��������������κ��豸�������ϵ��Ե����ͻ����ϲ鿴��� HTML ��ǣ����������������ú��ʵĹ��߽� HTML ���ת����������������ʽ����Ȼ HTML �ɹ��ˣ�Ϊʲô W3C ��Ҫ���� XML �أ�Ϊ�˻ش�������⣬��鿴��������ĵ���
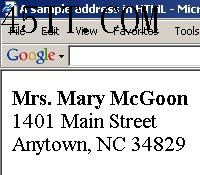
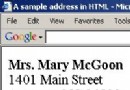
����HTML ��������������Ϊ����Ƶġ���ʹ����������鿴����� HTML �ĵ���������Ҳ��֪������ij���˵�������ַ����������ԣ���������ij���˵�������ַ����ʹ��һ��Ҳ����Ϥ����������ַ�ĸ�ʽ��������Ҳ��³����ʾʲô������Ϊ�ˣ������Ҿ������������ĵ��ĺ������ͼ���ǻۡ��ź����ǻ���������������������ĵ��еı�Ǹ�������������ʾ����Ϣ�������û�и����������Ϣ��ʲô��������֪������һ����ַ����������֪���� ��ʾ HTML ����Ҫ��ʾ HTML�������ֻ����ѭ HTML �ĵ��е�ָ��ɡ��α�Ǹ�����������µ�һ����ʾ������ͨ����ǰ����һ�����У����������б������������ǰ������һ�У�������֮��û�п��С������������ɫ�ؽ��ĵ���ʽ�����������Բ�֪�����ǵ�ַ��
���� HTML ����Ϊ����ɶ����� HTML �ĵ������ۣ��뿼�ǴӸõ�ַ��ȡ�������������������һ���� HTML ����в�������������㷨��������ʹ�ô������㷨����������ҵ������� <br> ��ǵĶ��䣬��ô����������ǵڶ������б�������һ������֮��ĵڶ����ʡ� �������ܸ��㷨�������ʾ�������ã�������ȫ����������ȫ��Ч�ĵ�ַ�����㷨�����������á���ʹ�����Ա�д�㷨���ҳ��κ��� HTML ��д�ĵ�ַ���������룬����������������б�ǵĶ��������������ַ�������п��ܱ�д�㷨���鿴���� HTML ���䲢�ҳ����е������������룬Ҳ�Ǽ������ѵġ� ���� XML �ĵ� ������������������һ������ XML �ĵ���ʹ�� XML�������Ը��ĵ��еı�Ǹ���ij�ֺ��⡣����Ҫ���ǣ�����Ҳ���״�����������Ϣ����ֻ��ͨ���ҵ� <postal-code> �� </postal-code> ���֮������ݣ������ϳ�Ϊ <postal-code> Ԫ�أ����Ϳ��ԴӸ��ĵ���ȡ�������롣 |