|
今天看到了一个很奇怪的问题,要读取Excel文件的文本框中的文本,例如这种:

本以为openxlpy可以读取,但查看openxlpy官方文档并没有找到相应的API,咨询了几个大佬,他们也没有处理过类似的问题。
无赖之下,我就准备发挥我较强的数据解析能力,自己写个方法来读取这些东西。
处理代码
xlsx文件的本质是xml格式的压缩包,解压文件做xml解析提取出相应的数据即可。
本来准备用lxml作xpath解析xml,但实际测试发现,这些xml文件存在大量的命名空间,解析起来异常复杂,试了好几个普通的xml解析的库,可以顺利解析,但我觉得还不如正则方便,所以我最终选择了使用正则表达式作xml解析。
最终处理代码如下:
import re
import os
import shutil
from zipfile import ZipFile
def read_xlsx_textbox_text(xlsx_file):
tempdir = tempfile.gettempdir()
basename = os.path.basename(xlsx_file)
xml_names = []
with ZipFile(xlsx_file) as zip_file:
for name in zip_file.namelist():
if name.startswith("xl/drawings/drawing"):
zip_file.extract(name, tempdir)
destname = f"{tempdir}/{name}"
xml_names.append(destname)
result = []
for xml_name in xml_names:
with open(xml_name, encoding="utf-8") as f:
text = f.read()
lines = re.findall("<a:p>(.*?)</a:p>", text)
for line in lines:
runs = re.findall("<a:t>(.*?)</a:t>", line)
result.append("".join(runs).replace('<', '<').replace(
'>', '>').replace('&', '&'))
return "\n".join(result)
测试一下:
result = read_xlsx_textbox_text("test.xlsx")
print(result)
结果:
什么是JSON?
就是一种数据格式;比如说,我们现在规定,有一个txt文本文件,用来存放一个班级的成绩;然后呢,我们规定,这个文本文件里的学生成绩的格式,是第一行,就是一行列头(姓名 班级 年级 科目 成绩),接下来,每一行就是一个学生的成绩。那么,这个文本文件内的这种信息存放的格式,其实就是一种数据格式。
学生 班级 年级 科目 成绩
张三 一班 大一 高数 90
李四 二班 大一 高数 80
ok,对应到JSON,它其实也是代表了一种数据格式,所谓数据格式,就是数据组织的形式。比如说,刚才所说的学生成绩,用JSON格式来表示的话,如下:
[{"学生":"张三", "班级":"一班", "年级":"大一", "科目":"高数", "成绩":90}, {"学生":"李四", "班级":"二班", "年级":"大一", "科目":"高数", "成绩":80}]
其实,JSON,很简单,一点都不复杂,就是对同样一批数据的,不同的一种数据表示的形式。
JSON的数据语法,其实很简单:如果是包含多个数据实体的话,比如说多个学生成绩,那么需要使用数组的表现形式,就是[]。对于单个数据实体,比如一个学生的成绩,那么使用一个{}来封装数据,对于数据实体中的每个字段以及对应的值,使用key:value的方式来表示,多个key-value对之间用逗号分隔;多个{}代表的数据实体之间,用逗号分隔。
...
这样我们就顺利实现了,从一个Excel文件中,读取全部的文本框的文本。
注意:如果你有啥特殊的其他需求,可以根据实际情况修改代码,也可以联系本文作者(小小明)进行相应的定制。
读取xls文件的文本框内容
上面的方法,仅支持xlsx格式文件的读取,如果要读取xls格式,我们需要先进行格式转换。
完整代码:
import win32com.client as win32
def read_xls_textbox_text(xls_file):
excel_app = win32.gencache.EnsureDispatch('Excel.Application')
try:
wb = excel_app.Workbooks.Open(xls_file)
xlsx_file = xls_file+"x"
wb.SaveAs(xlsx_file, FileFormat=51)
finally:
excel_app.Quit()
return read_xlsx_textbox_text(xlsx_file)
如果你希望存在同名的xlsx文件时不提示,关闭注释即可
测试读取:
print(read_xls_textbox_text(r"E:\tmp\test2.xls"))
结果:
我们的数据从哪里来?
互联网行业:网站、app、系统(交易系统。。)
传统行业:电信,人们的上网、打电话、发短信等等数据
数据源:网站、app
都要往我们的后台去发送请求,获取数据,执行业务逻辑;app获取要展现的商品数据;发送请求到后台进行交易和结账
后台服务器,比如Tomcat、Jetty;但是,其实在面向大量用户,高并发(每秒访问量过万)的情况下,通常都不会直接是用Tomcat来接收请求。这种时候,通常,都是用Nginx来接收请求,并且后端接入Tomcat集群/Jetty集群,来进行高并发访问下的负载均衡。
比如说,Nginx,或者是Tomcat,你进行适当配置之后,所有请求的数据都会作为log存储起来;接收请求的后台系统(J2EE、PHP、Ruby On Rails),也可以按照你的规范,每接收一个请求,或者每执行一个业务逻辑,就往日志文件里面打一条log。
网站/app会发送请求到后台服务器,通常会由Nginx接收请求,并进行转发
...
xls格式批量转xlsx
假如我们有一批xls文件,希望批量转换为xlsx:
我的实现方式是整个文件夹都转换完毕再关闭应用,这样相对来说处理更快一些,但可能更耗内存,代码如下:
import win32com.client as win32
from pathlib import Path
import os
def format_conversion(xls_path, output_path):
if not os.path.exists(output_path):
os.makedirs(output_path)
excel_app = win32.gencache.EnsureDispatch('Excel.Application')
try:
for filename in Path(xls_path).glob("[!~]*.xls"):
dest_name = f"{output_path}/{filename.name}x"
wb = excel_app.Workbooks.Open(filename)
wb.SaveAs(dest_name, FileFormat=51)
print(dest_name, "保存完成")
finally:
excel_app.Quit()
测试一下:
excel_path = r"F:\excel文档"
output_path = r"E:\tmp\excel"
format_conversion(excel_path, output_path)
结果:
E:\tmp\excel/008.离线日志采集流程.xlsx 保存完成
E:\tmp\excel/009.实时数据采集流程.xlsx 保存完成
E:\tmp\excel/011.用户访问session分析-模块介绍.xlsx 保存完成
E:\tmp\excel/012.用户访问session分析-基础数据结构以及大数据平台架构介绍.xlsx 保存完成
E:\tmp\excel/013.用户访问session分析-需求分析.xlsx 保存完成
E:\tmp\excel/014.用户访问session分析-技术方案设计.xlsx 保存完成
E:\tmp\excel/015.用户访问session分析-数据表设计.xlsx 保存完成
E:\tmp\excel/018.用户访问session分析-JDBC原理介绍以及增删改查示范.xlsx 保存完成
E:\tmp\excel/019.数据库连接池原理.xlsx 保存完成
...
批量提取xlsx文件的文本框文本
上面我们已经获得了一个xlsx文件的文件夹,下面我们的需求是,提取这个文件夹下每个xlsx文件的文本框内容将其保存为对应的txt格式。
处理代码:
from pathlib import Path
xlsx_path = r"E:\tmp\excel"
for filename in Path(xlsx_path).glob("[!~]*.xlsx"):
filename = str(filename)
destname = filename.replace(".xlsx", ".txt")
print(filename, destname)
txt = read_xlsx_textbox_text(filename)
with open(destname, "w") as f:
f.write(txt)
执行后,已经顺利得到相应的txt文件:
需求升级
上面的读取方法是将整个excel文件所有的文本框内容都合并在一起,但有时我们的excel文件的多个sheet都存在文本框,我们希望能够对不同的sheet进行区分:
下面我们改进我们的读取方法,使其返回每个sheet名对应的文本框文本,先测试一下。
首先解压所需的文件:
from zipfile import ZipFile
from pathlib import Path
import shutil
import os
import tempfile
import re
xlsx_file = "test3.xlsx"
tempdir = tempfile.gettempdir()
basename = os.path.basename(xlsx_file)
xml_names = []
sheets_names = None
ids = []
with ZipFile(xlsx_file) as zip_file:
for name in zip_file.namelist():
if name.startswith("xl/drawings/drawing"):
zip_file.extract(name, tempdir)
destname = f"{tempdir}/{name}"
xml_names.append(destname)
elif name == "xl/workbook.xml":
zip_file.extract(name, tempdir)
sheets_names = f"{tempdir}/{name}"
elif name.startswith("xl/worksheets/_rels/sheet"):
tmp = name.lstrip("xl/worksheets/_rels/sheet")
ids.append(int(tmp[:tmp.find(".")])-1)
print(xml_names, sheets_names, ids)
结果:
['C:\\Users\\Think\\AppData\\Local\\Temp/xl/drawings/drawing1.xml', 'C:\\Users\\Think\\AppData\\Local\\Temp/xl/drawings/drawing2.xml', 'C:\\Users\\Think\\AppData\\Local\\Temp/xl/drawings/drawing3.xml', 'C:\\Users\\Think\\AppData\\Local\\Temp/xl/drawings/drawing4.xml', 'C:\\Users\\Think\\AppData\\Local\\Temp/xl/drawings/drawing5.xml'] C:\Users\Think\AppData\Local\Temp/xl/workbook.xml [0, 1, 2, 4, 5]
读取sheet名称:
with open(sheets_names, encoding="utf-8") as f:
text = f.read()
sheet_names = re.findall(
'<sheet .*?name="([^"]+)" .*?/>', text)
tmp = []
for inx in ids:
tmp.append(sheet_names[inx])
sheet_names = tmp
sheet_names
结果:
['JSON', '数据库连接池', '实时数据采集', '工厂设计模式', '页面转化率']
解析:
result = {}
for sheet_name, xml_name in zip(sheet_names, xml_names):
with open(xml_name, encoding="utf-8") as f:
xml = f.read()
lines = re.findall("<a:p>(.*?)</a:p>", xml)
tmp = []
for line in lines:
runs = re.findall("<a:t>(.*?)</a:t>", line)
tmp.append("".join(runs).replace('<', '<').replace(
'>', '>').replace('&', '&'))
result[sheet_name] = "\n".join(tmp)
result
结果(省略了大部分文字):
{'JSON': '什么是JSON?....',
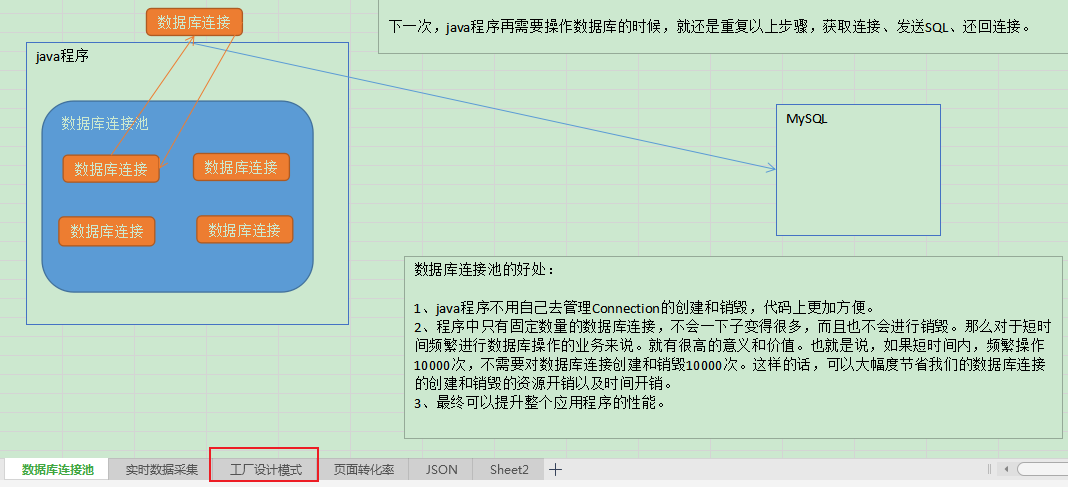
'数据库连接池': 'java程序\n数据库连接\n数据库连接\n数据库连接\nMySQL...',
'实时数据采集': '...实时数据,通常都是从分布式消息队列集群中读取的,比如Kafka....',
'工厂设计模式': '如果没有工厂模式,可能会出现的问题:....',
'页面转化率': '用户行为分析大数据平台\n\n页面单跳转化率,....'}
可以看到已经顺利的读取到每个sheet对应的文本框内容,而且一一对应。
分别读取每个sheet对应文本框文本
我们整合并封装一下上面的过程为一个方法:
import re
import os
from zipfile import ZipFile
import tempfile
def read_xlsx_textbox_text(xlsx_file, combine=False):
tempdir = tempfile.gettempdir()
basename = os.path.basename(xlsx_file)
xml_names = []
sheets_names = None
ids = []
with ZipFile(xlsx_file) as zip_file:
for name in zip_file.namelist():
if name.startswith("xl/drawings/drawing"):
zip_file.extract(name, tempdir)
destname = f"{tempdir}/{name}"
xml_names.append(destname)
elif name == "xl/workbook.xml":
zip_file.extract(name, tempdir)
sheets_names = f"{tempdir}/{name}"
elif name.startswith("xl/worksheets/_rels/sheet"):
tmp = name.lstrip("xl/worksheets/_rels/sheet")
ids.append(int(tmp[:tmp.find(".")])-1)
with open(sheets_names, encoding="utf-8") as f:
text = f.read()
sheet_names = re.findall(
'<sheet .*?name="([^"]+)" .*?/>', text)
tmp = []
for inx in ids:
tmp.append(sheet_names[inx])
sheet_names = tmp
result = {}
for sheet_name, xml_name in zip(sheet_names, xml_names):
with open(xml_name, encoding="utf-8") as f:
xml = f.read()
lines = re.findall("<a:p>(.*?)</a:p>", xml)
tmp = []
for line in lines:
runs = re.findall("<a:t>(.*?)</a:t>", line)
tmp.append("".join(runs).replace('<', '<').replace(
'>', '>').replace('&', '&'))
result[sheet_name] = "\n".join(tmp)
if combine:
return "\n".join(result.values())
return result
调用方式:
result = read_xlsx_textbox_text("test3.xlsx")
print(result)
可以传入combine=True,将sheet的结果合并到一个文本,但这样不如直接调用之前编写的方法。
批量提取文本框文本分sheet单独保存
下面,我们的需求是对每个xlsx文件创建一个同名文件夹,每个文件夹下根据sheet名称单独保存文本框的文本。
处理代码:
from pathlib import Path
import os
xlsx_path = r"E:\tmp\excel"
for filename in Path(xlsx_path).glob("[!~]*.xlsx"):
dest = filename.with_suffix("")
if not os.path.exists(dest):
os.mkdir(dest)
filename = str(filename)
print(filename, dest)
result = read_xlsx_textbox_text(filename)
for txtname, txt in result.items():
with open(f"{dest}/{txtname}", "w") as f:
f.write(txt)
print(f"\t{dest}/{txtname}")
经测试顺利的为每个excel文件创建了一个目录,每个目录下根据哪些sheet存在文本框就有相应的sheet名文件。
使用Python调用VBA解决需求
VBA官方文档地址:https://docs.microsoft.com/zh-cn/office/vba/api/overview/excel
整体而言,上面自行解析xml的方法还是挺麻烦的,在写完上面的方法后我灵机一动,VBA不就有现成的读取文本框的方法吗?而Python又可以全兼容的写VBA代码,那问题就简单了。通过VBA,不仅代码简单,而且不用考虑格式转换的问题,直接可以解决问题,读取代码如下:
import win32com.client as win32
def read_excel_textbox_text(excel_file, app=None, combine=False):
if app is None:
excel_app = win32.gencache.EnsureDispatch('Excel.Application')
else:
excel_app = app
wb = excel_app.Workbooks.Open(excel_file)
result = {}
for sht in wb.Sheets:
if sht.Shapes.Count == 0:
continue
lines = []
for shp in sht.Shapes:
try:
text = shp.TextFrame2.TextRange.Text
lines.append(text)
except Exception as e:
pass
result[sht.Name] = "\n".join(lines)
if app is None:
excel_app.Quit()
if combine:
return "\n".join(result.values())
return result
测试读取:
result = read_excel_textbox_text(r'F:\jupyter\test\提取word图片\test3.xlsx')
print(result)

顺利读出结果。
批量处理:
from pathlib import Path
import os
xlsx_path = r"E:\tmp\excel"
app = win32.gencache.EnsureDispatch('Excel.Application')
try:
for filename in Path(xlsx_path).glob("[!~]*.xls"):
dest = filename.with_suffix("")
if not os.path.exists(dest):
os.mkdir(dest)
filename = str(filename)
print(filename, dest)
result = read_excel_textbox_text(filename, app)
for txtname, txt in result.items():
with open(f"{dest}/{txtname}", "w") as f:
f.write(txt)
print(f"\t{dest}/{txtname}")
finally:
app.Quit()
经测试,VBA处理的缺点也很明显,63个文件耗时达到25秒,而直接解析xml耗时仅259毫秒,性能差别不在一个数量级。
使用xlwings解决需求
苹果电脑是不支持VBA的,上面调用VBA的代码对于苹果电脑来说无效,但所幸的是xlwings在0.21.4版本中新增了访问文本框文本的属性text。
作为Windows上Pywin32和Mac上appscript的智能包装的xlwings,已经通过appscript实现了在Mac系统上对文本框文本的访问:
import xlwings as xw
app = xw.App(visible=True, add_book=False)
wb = app.books.open(r'test3.xlsx')
for sht in wb.sheets:
print("-------------", sht.name)
for shp in sht.shapes:
if hasattr(shp, 'text') and shp.text:
print(shp.text)
wb.close()
app.quit()
注意:如果你的xlwings没有这个属性,请注意升级:
pip install xlwings -U
总结
读取excel中的数据,基本没有VBA干不了的事,python调用VBA也很简单,直接使用pywin32即可。当然2007的xlsx本质上是xml格式的压缩包,解析xml文本也没有读不了的数据,只是代码编写起来异常费劲,当然也得你对xlsx的存储原理较为了解。
这样VBA与直接解析xml的优劣势就非常明显了:
-
VBA是excel应用直接支持的API,代码编写起来相对很简单,但执行效率低下。苹果电脑无法使用VBA,可以使用xlwings已经封装好的方法实现。
-
直接解析xml文件,需要对excel的存储格式较为了解,编码起来很费劲,但是执行效率极高。
|